Abstract
Text-to-3D generation has achieved remarkable success in digital object creation, attributed to the utilization of large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. The complexity and vast scale of urban scenes, characterized by numerous elements and intricate arrangement relationships, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations via a paradigm shift in the current text-to-3D methodology, accomplished through a compositional 3D layout representation serving as an additional prior. The 3D layout comprises a set of semantic primitives with simple geometric structures (e.g., cuboids, ellipsoids, and planes), and explicit arrangement relationships. It complements textual descriptions, and meanwhile enables steerable generation. Based on the 3D layout representation, we propose two modifications to the current text-to-3D paradigm (1) We introduce Layout-Guided Variational Score Distillation (LG-VSD) to address model optimization inadequacies. It incorporates the geometric and semantic constraints of the 3D layout into the the fabric of score distillation sampling process, effectuated through an elegant formula extension into a conditional manner. (2) To handle the unbounded nature of the urban scenes, we represent the 3D scene with a Scalable Hash Grid structure, which incrementally adapts to the growing scale of urban scenes. Extensive experiments substantiate the robustness of our framework, showcasing its capability to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations (e.g., style editing, object manipulation, etc.), showing the complementary powers of both 3D layout prior and text-to-image diffusion models in our framework for steerable urban scene generation.
Method overview
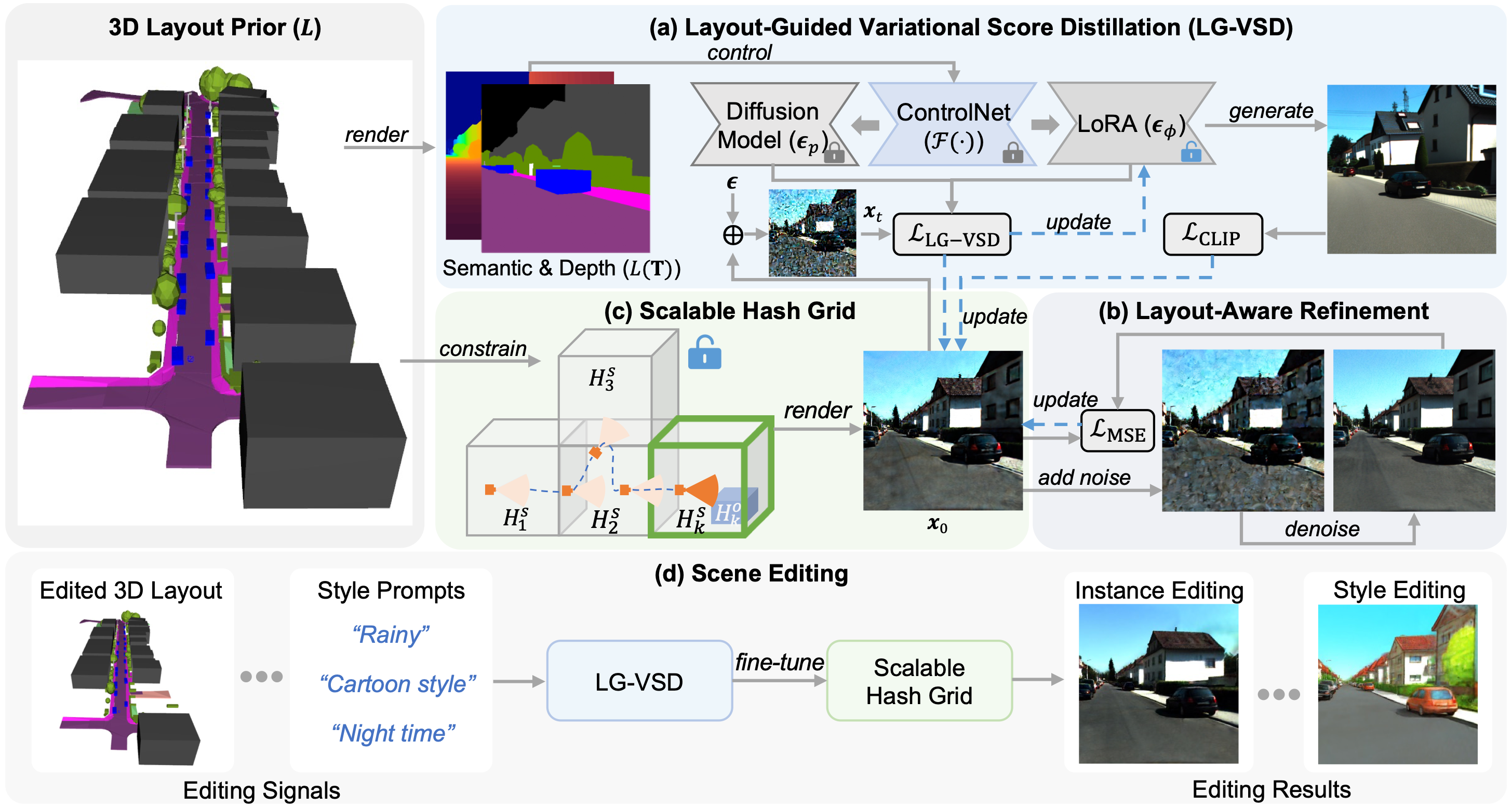
Overview of Urban Architect. We introduce Urban Architect, a method that generates urban-scale 3D scenes with 3D layout instruction and textural descriptions. The scene is represented by a neural field that is optimized by distilling a pre-trained diffusion model in a conditional manner. (a) Rather than relying solely on the text-based guidance, we propose to control the distilling process of Variational Score Distillation (VSD) via the 3D layout of the desired scene, introducing Layout-Guided Variational Score Distillation (LG-VSD). (b) We refine the local details via a layout-aware refinement strategy. (c) To model unbounded urban scenes, we discretize the 3D representation into a scalable hash grid. (d) We support various scene editing effects by fine-tuning the generated scene.
Video
Results
Diverse 3D results
Comparison with other methods
EG3D
CC3D
Ours
Transfer to different weather and time
"night time"
"rainy"
"in winter, with snow"
Transfer to different style
"minecraft style"
"cartoon style"
"Vangogh paint"
Transfer to different city
"in Kyoto"
"in Hawaii"
"in Venice"
Object manipulation
Translation
Rotation
Scaling